파이썬(python) & 크롤링(crawling) - 013
[파이썬(python) & 크롤링(crawling) - 013]
크롤링(Crawling) 기본 - 13
크롤링(Crawling) - find
find 메소드는 태그를 이용하여 원하는 부분을 추출
태그는 이름(name), 속성(attribut), 값(value)로 구성되어 있기 때문에
find로 해당 이름이나 속성, 값을 특정하여 태그를 찾을 수 있다.
tag = "<p class='example' id='test01'> Hello World! </p>"
# 태그 이름만 특정
soup.find('p')
# 태그 속성만 특정
soup.find(class_='example')
soup.find(attrs = {'class':'exmaple'})
# 태그 이름과 속성 모두 특정
soup.find('p', class_='example')
크롤링(Crawling) - select
select는 CSS Selector로 tag 객체를 찾아 반환한다.
CSS에서 HTML을 태깅하는 방법을 활용한 메소드
#태그 찾기
items = soup.select("title")
#특정 태그 아래에 있는 태그 찾기
items = soup.select("div a") #div 태그 아래에 있는 a 태그 찾기
#특정 태그 바로 아래에 있는 태그 찾기
items = soup.select("head > title")
items = soup.select("head > #link1") #아이디로 태그 찾음
#태그들의 형제 태그 찾기
items = soup.select("#link1 ~ .sister")
items = soup.select("#link1 + .sister")
#CSS class로 태그 찾기
items = soup.select(".sister")
#ID값으로 태그 찾기
items = soup.select("#link1")
# 태그.클래스이름1.클래스이름2.~~~
items = soup.select('li.course.paid')
find & select
- find 메소드와 select 중 무엇이 사용에 용이한가?
- find와 select는 태그 이름, 속성, 속성값을 특정하는 방식은 같다
하지만 CSS는 이 외에도 다양한 선택자(selector)를 갖기 때문에 여러 요소를 조합하여 태그를 특정하기 쉽다. -
예를 들어 특정 경로의 태그를 객체로 반환하고 싶을 때, find의 경우 아래와 같이 반복적으로 코드를 작성해야 하는 반면
select는 직접 하위 경로를 지정할 수 있다.- find
- soup.find(‘div’).find(‘p’)
- select
- soup.select_one(‘div > p’)
- soup.select_one(‘div > p’)
- find
- 그러므로 다양한 조건 활용과 태그를 직관적으로 찾기 위해서는 find보다는 select를 사용하는 게 유리.
크롤링 기본코드
# 웹페이지를 가져오는 라이브러리 requests를 import
import requests
# 가져온 웹페이지를 기반으로 특정한 데이터를 추출할 수 있도록 분석해주는 라이브러리(BeautifulSoup)를 import하고
# 이름을 간략하게 bs4로 변경
from bs4 import BeautifulSoup
# 크롤링을 하고자 하는 웹페이지(ex. 다음 뉴스)를 가져와서(get) res라는 변수에 담기
res = requests.get('https://news.v.daum.net/v/20220407163404588')
# 담은 페이지(res.content)를 html.parser를 이용 분해(parsing)해서 soup이라는 변수에 담기
soup = BeautifulSoup(res.content, 'html.parser')
# find라는 함수를 이용해 필요한 데이터 하나(ex. title 그리고 h1 태그)를 추출해서 mydata라는 변수에 담기
mydata = soup.find('title', 'h1')
# mydata에 담긴 내용 중 text만 빼서(get_text()) 출력하기
print(mydata) # 태그를 포함한 데이터가 추출됨.
print(mydata.string) # 데이터 중 태그 등을 제외한 String Data만 추출됨
print(mydata.get_text()) # 데이터 중 태그 등을 제외한 text만 추출됨.
- 크롤링 할 데이터를 지정할때는 크롬 브라우저의 페이지소스 보기를 한 후 개발자도구(f12) 좌측 상단에 있는
검사할 페이지요소 선택(화살표 모양의 아이콘, Ctrl+Shift+C)을 클릭하여 지정하고자 하는 요소를 클릭한 후
우측 개발자도구-요소(element)에 나타난 태그를 기반으로 지정한다.
# 여러개의 동일 tag에 있는 데이터를 추출할 때 find_all() 함수를 사용한다.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://news.v.daum.net/v/20220407163404588')
soup = BeautifulSoup(res.content, 'html.parser')
# p태그 여러개를 추출해서 list에 담는다.
data_list = soup.find_all('p')
# 추출된 data가 담긴 list를 for문을 이용해 하나씩 출력한다.
for data in data_list:
print(data.get_text()) # 데이터 중 태그 등을 제외한 text만 추출됨.
- 세부 데이터 추출하기
- find()로 더 크게 감싸는 HTML 태그를 추출하고 그 데이터에서 find_all()로 원하는 부분을 추출
- 추출된 데이터는 object임
import requests
from bs4 import BeautifulSoup
res = requests.get('https://sports.news.naver.com/wfootball/index')
soup = BeautifulSoup(res.content, 'html.parser')
section = soup.find("ol")
# print(section)
data = section.find_all('a')
for item in data:
print (item.get_text().strip())
# 출력값
호날두도 박지성은 감사했다, "맨유 위해 희생했던 선수"
'이탈리아의 역적' 모레노 주심 심경 고백...'나의 유일한 실수는 황선홍 퇴장 주지 않은 것'
'괴물' 김민재 토트넘 이적 가시화, 터키 언론 "토트넘 김민재 바이아웃 305억 제시"
'부러운 양반' 퍼거슨, 은퇴 이후에도 일주일에 '4억 이상' 벌어들여
'최고에서 최악으로' 레알 지배했던 캉테, 1년 만에 무슨 일이?
손흥민, 훈련 중 토트넘 코치와 유쾌한 말 다툼
‘괴물 공격수 돌아온다고?’ 두 팔 벌려 환영...단, 조건은 있지!
“어라, 강팀에 약하네?” 1,085억 골잡이 압박 시작됐다
첼시가 떠나보낸 유망주 몸값만 '약 4,735억', 근데 또?
'너무 잘하는데?' 로메로 향한 찬사 "마치 넥스트 반 다이크 or 디아스"
# find는 select_one, find_all은 select로 대체 가능
- 추출된 데이터의 추가 가공
- ex) (basic)-개발자가 실제 사용하는 함수 모음[5]
- 위의 예와 같이 실제 필요한 문구는 ‘1.개발자가 실제 사용하는 함수 모음’으로 앞쪽의 글자와 뒷쪽의 숫자 부분을 삭제하고자 하는 경우
# 1. split 함수 이용해 [5] 날리기 ==> '['를 기준으로 쪼갠 후 하여 앞쪽 데이터[0]만 선택
print(title.get_text().split('[')[0])
# 출력값 : (basic) 개발자가 실제 사용하는 함수 모음
# 2. split 함수 이용해 '(basic)-' 부분 날리기 ==> '-'를 기준으로 쪼갠 후 하여 뒷쪽 데이터[1]만 선택
print(title.get_text().split('[')[0].split('-')[1])
# 3. strip 함수 이용해 공백 또는 글 간 빈줄 날리기
print(title.get_text().split('[')[0].split('-')[1].strip())
# 4. 위의 결과값에 번호 추가하여 출력하기(for 문에 하나의 인자를 더 추가)
for index, title in enumerate(titles):
# ==> 숫자 인자로 index를 추가했음.
# enumerate의 경우 숫자는 0부터 시작하기에 1부터 시작하게 조정 필요
print (str(index+1) + '.', title.get_text().split('[')[0].split('-')[1].strip())
class 선택자와 id 선택자 선택 고려사항
- class - 한페이지 내 여러번 반복될 필요가 있는 스타일에 사용, 글자색, 글자 굵기 등
- id - 유일하게 단 한번 적용될 스타일에 사용, 웹문서 안에서 요소의 배치방법 지정
- id가 class보다 우선순위가 높음
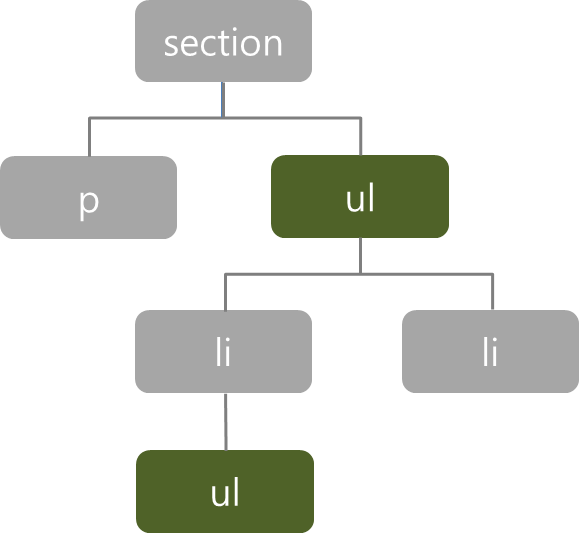
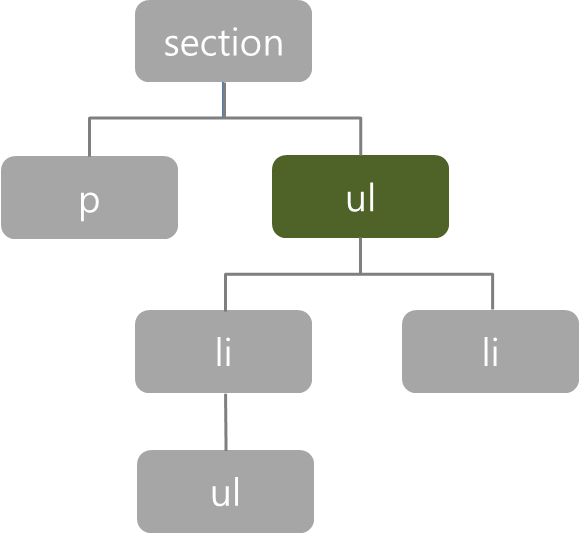
복합선택자
[하위선택자(왼쪽)와 자식선택자(오른쪽)]
- 하위선택자는 부모 요소에 포함된 ‘모든’ 하위 요소에 스타일을 적용한다.
- 자식선택자는 부모의 바로 아래 자식요소에만 적용된다.
- 하위선택자 : section ul { border:1px dotted black; }
- 자식선택자 : section > ul { border:1px dotted black; }
[인접형제선택자(위쪽)와 일반형제선택자(아래쪽)]
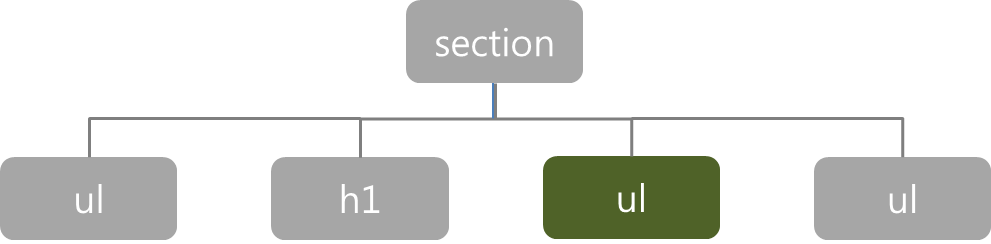
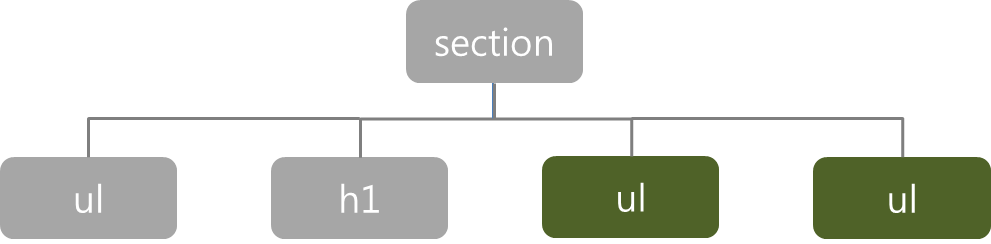
- 같은 부모 요소를 가지는 요소들을 형제관계라고 한다.
HTML 문서에 먼저 쓰여지는 것을 기준으로 먼저 나오는 요소를 ‘형 요소’,
나중에 나오는 요소를 ‘동생 요소’라고 한다. - 인접 형제선택자 : 형제 중 첫번째 동생 요소가 조건을 충족시킬 때 스타일을 적용
- 일반 형제선택자 : 조건을 충족하는 모든 동생요소에 스타일을 적용
- 인접 형제선택자 : h1+ul { background: yellowgreen; color: darkgreen; }
- 일반 형제선택자 : h1~ul { background: yellowgreen; color: darkgreen; }
[속성 선택자(Attribute Selectors)]
- 태그안의 특정 속성들에 따라 스타일을 지정
- 속성 값의 조건에 따라 다양한 스타일을 지정할 수 있어 활용도가 높은 스타일 지정방식
- 속성선택자는 모두 앞쪽에서 태그명과 대괄호[] 사이에 속성에 관련된 내용을 삽입
- ex. a[href], input[type=”text”]
[가상 클래스 선택자(Pseudo-Classes Selectors)]
- 가상클래스는 웹문서의 소스에는 실제로 존재하지 않지만 필요에 의해 임의로 가상의 선택자를 지정하여 사용하는 것을 말함
- 선택자 뒤에 :가상이벤트를 붙이면 특정 이벤트마다 적용 할 스타일을 설정할 수 있으며 이를 가상(추상)클래스라 한다.
- 대표적인 가상클래스 예시
- :link - 방문한 적이 없는 링크
- :visited - 방문한 적이 있는 링크
- :hover - 마우스를 롤오버 했을 때
- :active - 마우스를 클릭했을 때
- :focus - 포커스 되었을 때 (input 태그 등)
- :first - 첫번째 요소
- :last - 마지막 요소
- :first-child - 첫번째 자식
- :last-child - 마지막 자식
- :nth-child(2n+1) - 홀수 번째 자식
댓글남기기